http://graphics.cs.cmu.edu/projects/DTP/
An Uncertain Future: Forecasting from Static Images using Variational Autoencoders
People
...
Abstract
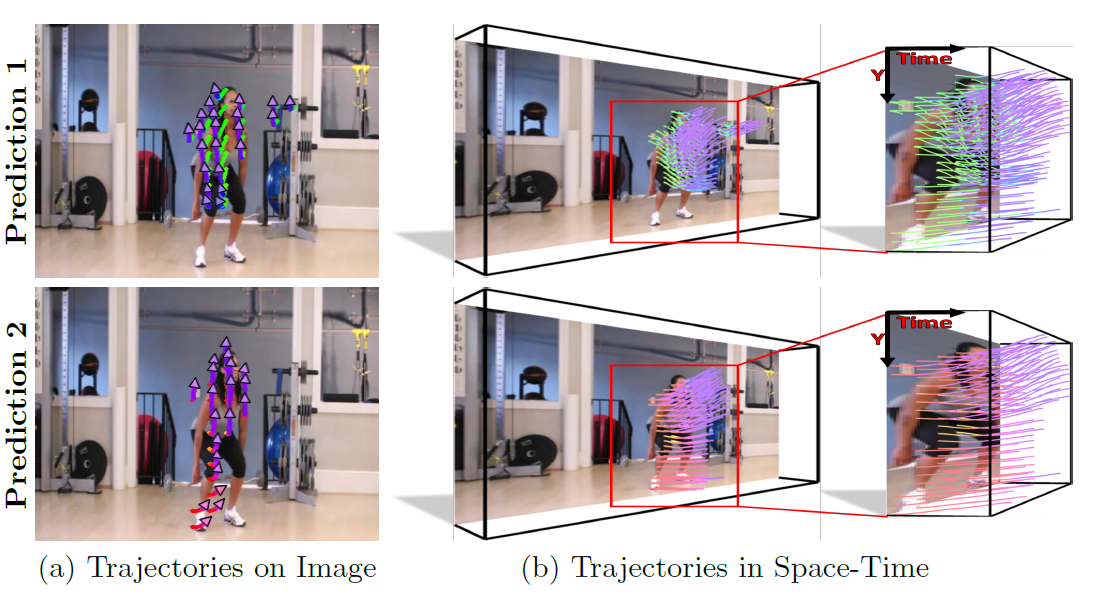
In a given scene, humans can often easily predict a set of immediate future events that might happen. However, generalized pixel-level anticipation in computer vision systems is difficult because machine learning struggles with the ambiguity inherent in predicting the future. In this paper, we focus on predicting the dense trajectory of pixels in a scene, specifically what will move in the scene, where it will travel, and how it will deform over the course of one second. We propose a conditional variational autoencoder as a solution to this problem. In this framework, direct inference from the image shapes the distribution of possible trajectories, while latent variables encode any necessary information that is not available in the image. We show that our method is able to successfully predict events in a wide variety of scenes and can produce multiple different predictions when the future is ambiguous. Our algorithm is trained on thousands of diverse, realistic videos and requires absolutely no human labeling. In addition to non-semantic action prediction, we find that our method learns a representation that is applicable to semantic vision tasks.
Videos - Selected Examples
|
|
Paper

|
Jacob Walker, Carl Doersch, Abhinav Gupta, and Martial Hebert, An Uncertain Future: Forecasting from Static Images using Variational Autoencoders, [Paper (Arxiv Version) (5.8MB)] [ECCV Version (5.6MB)] |
BibTeX
@inproceedings{@inproceedings{of_eccv2016,
author="Jacob Walker and Carl Doersch and Abhinav Gupta and Martial Hebert",
title="An Uncertain Future: Forecasting from Static Images Using Variational Autoencoders",
booktitle="European Conference on Computer Vision",
year="2016"
}
Code
Code
Funding
This research is supported by:
- NSF IIS-1227495
Comments, questions to Jacob Walker