http://graphics.cs.cmu.edu/projects/ptf/
Patch to the Future: Unsupervised Visual Prediction
Presented at CVPR, 2014
People
...
Abstract
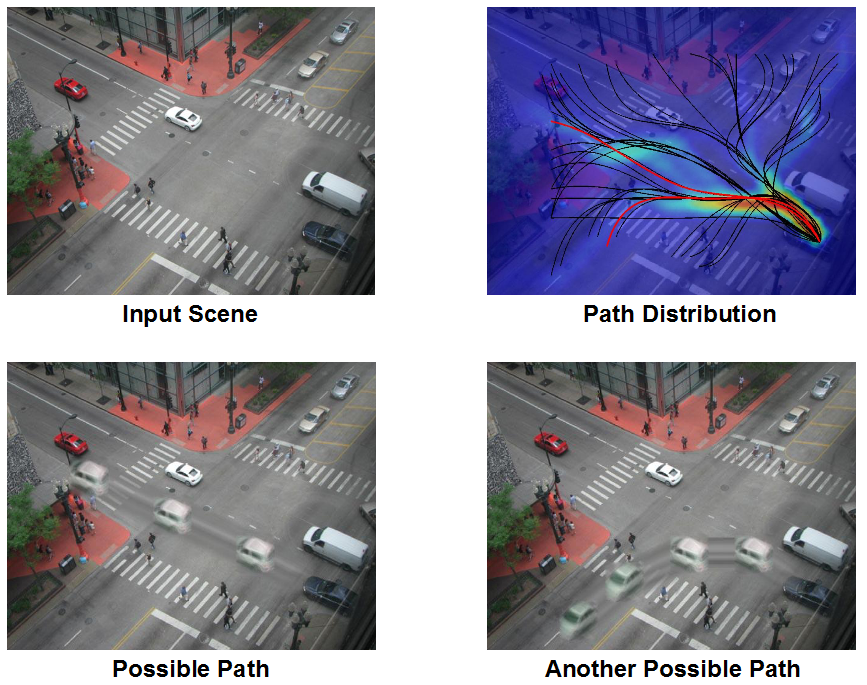
In this paper we present a conceptually simple but surprisingly powerful method for visual prediction which combines the effectiveness of mid-level visual elements with temporal modeling. Our framework can be learned in a completely unsupervised manner from a large collection of videos. However, more importantly, because our approach models the prediction framework on these mid-level elements, we can not only predict the possible motion in the scene but also predict visual appearances — how are appearances going to change with time. This yields a visual “hallucination” of probable events on top of the scene. We show that our method is able to accurately predict and visualize simple future events; we also show that our approach is comparable to supervised methods for event prediction.
Videos
|
Here is an example of possible paths within the scene above. |
|
Here is an example of a car avoiding a bus and taking a right. |
Paper

|
Jacob Walker, Abhinav Gupta, and Martial Hebert, Patch to the Future: Unsupervised Visual Prediction, In Computer Vision and Pattern Recognition (2014). [Paper (8MB)] [Poster (20MB)] [Presentation (57MB)] |
BibTeX
@inproceedings{ptf_cvpr2014,
author="Jacob Walker and Abhinav Gupta and Martial Hebert",
title="Patch to the Future: Unsupervised Visual Prediction",
booktitle="Computer Vision and Pattern Recognition",
year="2014"
}
Code
Code (206MB)
Funding
This research is supported by:
- NSF IIS-1227495
Comments, questions to Jacob Walker